데이터 분석 심화_머신러닝 실습
선형회귀_고객 연간 지출액 예측
0. 라이브러리 불러오기
-sklearn.model_selection.train_test_split: 데이터를 학습 셋과 테스트 셋으로 나누는 도구
-statsmodels.stats.outliers_influence.variance_inflation_factor: 다중공선성을 수치로 계산하는 도구
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from statsmodels.stats.outliers_influence import variance_inflation_factor
import statsmodels.api as sm
from sklearn.metrics import r2_scoredf_ec = pd.read_csv("../../../../data/ecommerce.csv")
print(df_ec.shape)
df_ec.head(3)
1. 탐색적 데이터 분석
1) 수치형 변수들의 기술통계량 살펴보기
desc_stats = df_ec.describe()
desc_stats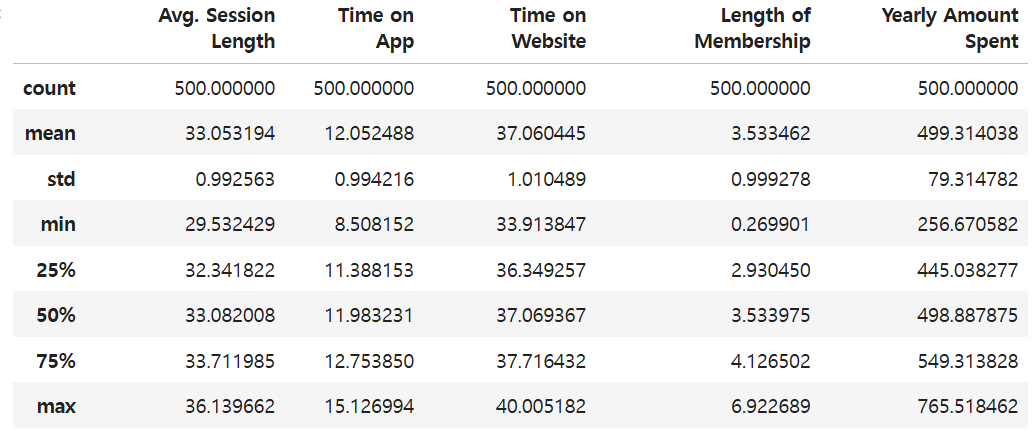
2) 고객 연간 지출액 히스토그램 그리기
-kde: 히스토그램 위에 곡선 그려줌(Kernel Density Estimation, 커널 밀도 추정)
plt.figure(figsize=(10, 6))
sns.histplot(df_ec['Yearly Amount Spent'], kde=True)
plt.title("Distribution od Yearly Amount Spent");
3) 상관관계 분석 후 히트맵으로 표현
df_ec.info()
-select_dtypes(include / exclude = 데이터 타입)
※여러 데이터타입 한번에 지정할 때는 리스트[] 사용
corr = df_ec.select_dtypes(include=['float64']).corr()
corrsns.heatmap(corr, annot=True, fmt='.2f', cmap='coolwarm');

4) 모든 수치형 변수들 간 관계 보기
-pairplot: 대각선은 자기 자신과의 관계이므로 히스토그램을 그리고, 나머지 칸은 두 변수 간 산점도를 그린 그래프
-sns.pairplot(데이터프레임): 페어 플롯 그림(object 자동 제외)
sns.pairplot(df_ec);
5) 멤버십 기간과 연간 지출액 간 관계 조사
-jointplot(결합 분포 그래프): 중앙에는 두 변수의 산점도, 상단/우측에는 각 변수가 단독으로 어떻게 분포되어 있는지 히스토그램
-sns.jointplot(data=데이터프레임, x=가로축 변수명, y=세로축 변수명, 옵션)
-kind: 두 데이터의 관계를 어떤 스타일로 요약해서 보여줄 것인지 지정
- 'scatter'(표준): 점을 찍어 전체적인 분포를 봄
- 'reg': 산점도 위에 회귀선 그림
- 'kde': 점 대신 곡선으로 표현
plt.figure(figsize=(10, 6))
sns.jointplot(x='Length of Membership', y='Yearly Amount Spent', data=df_ec, kind='reg');
2. 선형회귀 모델링
1) 변수 및 학습 셋 분리
-종속변수인 Yearly Amount Spent를 제외한 수치형 변수들을 모두 독립변수로 설정
# 독립변수, 종속변수 세팅
X = df_ec.select_dtypes(include=['float64']).drop(columns=['Yearly Amount Spent'])
y = df_ec['Yearly Amount Spent']-train_test_split(독립변수, 종속변수): 학습 셋과 테스트 셋 분리
-test_size=숫자: 테스트 데이터의 비율(기본값 0.25)
-train_size=숫자: 학습 데이터의 비율(test_size 정하면 자동으로 채워짐)
-random_state=숫자: 무작위로 섞을 때 사용하는 난수 번호표(번호 고정하면 다시 실행해도 동일)
# 학습셋, 테스트셋 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state=100)※언패킹(Unpacking): 변수명 콤마로 나열 후 여러 변수를 한번에 정의
2) 선형회귀 적합
X_train_const = sm.add_constant(X_train) # 모델에 상수항 추가
X_test_const = sm.add_constant(X_test)# 모델 생성 및 학습 (최소제곱법 : OLS, Ordinary Least Squares)
ls = sm.OLS(y_train, X_train_const).fit()
ls.summary()

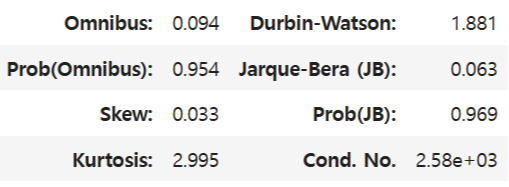
※Omnibus(옴니버스 검정): 잔차의 정규성(0에 가까울수록 좋음)
Priob(Omnibus)(옴니버스 검정 확률값): 정규분포일 확률(0.05보다 커야 함)
Jarque-Bera(JB)(자크-베라 검정): 잔차의 왜도/첨도 기반 정규성(0에 가까울수록 좋음)
Prob(JB)(자크-베라 검정 확률값): 정규분포일 확률(0.05보다 커야 함)
Durbin-Watson(더빈-왓슨 통계량): 잔차의 자기상관성(2에 가까울수록 좋음)
Cond.No.(조건지수): 다중공선성(30보다 작을수록 좋음)
# 학습된 모델(ls)을 사용하여 테스트 데이터의 예측값 생성
y_pred = ls.predict(X_test_const)
# 실제값(y_test)과 예측값(y_pred)을 비교하여 R2 계산
test_r2 = r2_score(y_test, y_pred)
print(f"테스트 데이터 R2 결정계수: {test_r2:.4f}")
# >>> 테스트 데이터 R2 결정계수: 0.9796→ AI의 해석
분석 결과, 이 모델은 과적합보다는 데이터 자체가 매우 강력한 선형 관계를 갖고 있는 경우로 판단됩니다.
Train R^2: 0.9860, Test R^2: 0.9796 두 값의 차이가 매우 적습니다.
만약 과적합이었다면 학습셋은 0.98인데 테스트셋은 0.7이나 0.8 정도로 크게 떨어졌을 것입니다.
따라서 이 모델은 새로운 데이터에 대해서도 예측력이 매우 우수하다고 볼 수 있습니다.
1. 유의한 독립변수 (p-value < 0.05)
Length of Membership (멤버십 유지 기간): p-value가 0.000으로 가장 유의하며, 회귀 계수(coef)도 약 61.82로 지출액에 가장 큰 영향을 미칩니다.
Time on App (앱 접속 시간): p-value가 0.000으로 매우 유의합니다.
Avg. Session Length (평균 세션 시간): p-value가 0.000으로 매우 유의합니다.
2. 유의하지 않은 독립변수 (p-value > 0.05)
Time on Website (웹사이트 접속 시간): p-value가 0.533입니다. 이는 통계적 유의 수준인 0.05보다 훨씬 크기 때문에,
이 모델에서는 웹사이트 접속 시간이 연간 지출액에 유의미한 영향을 주지 못한다고 해석할 수 있습니다.
요약 및 제언
분석 결과, 고객의 지출액을 늘리기 위해서는 웹사이트보다는 앱(App) 환경 개선과 멤버십 유지 기간(Customer Retention)을 관리하는 것이 훨씬 효과적이라는 인사이트를 얻을 수 있습니다.
유의하지 않게 나타난 'Time on Website' 변수는 향후 모델 고도화 시 제거를 검토해 볼 수 있습니다.
3) 다중공선성 확인
-VIF(Variance Inflation Factor, 분산 팽창 요인): 독립변수들끼리 얼마나 중복되는 정보를 가지고 있는지 수치화
→ 값이 작을수록 좋으며, 5 이상이면 주의 필요, 10 이상이면 다중공선성 발생으로 간주(해당 변수 삭제/결합 必)
-variance_inflation_factor(전체 독립변수 행렬, 검사할 변수 인덱스): 다중공선성 정량화
# 1. VIF를 계산할 독립변수들만 선택 (상수항 포함)
vif_data = X_train_const
# 2. VIF 계산을 위한 빈 데이터프레임 생성
vif_df = pd.DataFrame()
vif_df["feature"] = vif_data.columns
# 3. 각 컬럼(변수)별로 VIF 값 계산
# i번째 변수의 VIF를 구하기 위해 values와 인덱스 i를 전달합니다.
vif_df["VIF"] = [variance_inflation_factor(vif_data.values, i)
for i in range(len(vif_data.columns))] # 리스트 컴프리헨션
# 4. 결과 출력
print(vif_df.sort_values(by="VIF", ascending=False))
→ AI의 해석
변수들끼리 서로 너무 밀접하게 연관되어 있어 R^2가 가짜로 높아진 것은 아닌지 VIF(분산 팽창 인수)를 확인했습니다.
모든 독립변수의 VIF 지수가 1.01 내외로 측정되었습니다.
일반적으로 VIF가 10 이상이면 위험, 5 이상이면 주의로 보는데,
1에 가깝다는 것은 변수 간의 독립성이 매우 잘 유지되고 있다는 뜻입니다.
데이터 합치기
1. concat
1) 데이터프레임 준비
df1 = pd.DataFrame({'A': [1,3,5,7,9],
'B': [11,12,13,14,15],
'C': [0,1,2,3,4],
'D': [101,102,103,104,105]},
index = [1,2,3,4,5] )
df1df2 = pd.DataFrame({'A': [2,4,6,8,10],
'B': [1,2,3,4,5],
'C': [30,31,32,33,34],
'D': [1011,1021,1031,1041,1051]},
index = [6,7,8,9,10])
df2
2) 위아래로 합치기
-pd.concat([데이터프레임1, 데이터프레임2], 옵션): 데이터프레임1, 2를 위아래로 합침
-axis=0(기본값) / 1: 데이터프레임을 어느쪽으로 합칠지(위아래 / 양옆) 결정
pd.concat([df1, df2])


3) 양옆으로 합치기
-데이터프레임.set_index(): 데이터프레임의 특정 컬럼을 행 인덱스로 지정(기존의 숫자 인덱스 0, 1, 2, ... 사라짐)
-데이터프레임.reset_index(): 인덱스를 초기화하여 0, 1, 2, ...순서로 다시 번호 붙임
-drop: 기존 인덱스를 버릴지 결정
- False(기본값): 기존 인덱스가 새로운 'index'라는 이름의 열로 이동
- True: 기존 인덱스를 완전히 삭제
-inplace: 원본 데이터를 바로 바꿀지 결정
- False(기본값): 바뀐 결과물을 새로운 변수에 담아야 함
- True: 원본 데이터프레임이 즉시 수정됨
df1.reset_index(drop=True, inplace=True)
df1df2.reset_index(drop=True, inplace=True)
df2pd.concat([df1, df2], axis=1)
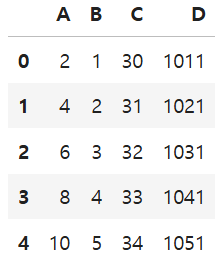
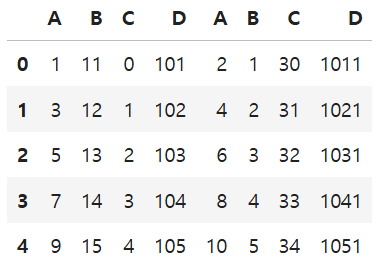
※pd.concat(axis=1)은 인덱스 번호가 같은 것 끼리만 한 줄에 세움 → 짝이 없는 부분은 NaN으로 채움
2. merge
1) 데이터프레임 준비
df3 = pd.DataFrame({'id': ['X01','X02','X03','X04','X05'],
'A': [1,3,5,7,9],
'B': [11,12,13,14,15],
'C': [0,1,2,3,4],
'D': [101,102,103,104,105] })
df3df4 = pd.DataFrame({'id': ['X01','X02','X03','X04','X06'],
'E': [2,4,6,8,10],
'F': [1,2,3,4,5],
'G': [30,31,32,33,34],
'H': [1011,1021,1031,1041,1051] })
df4
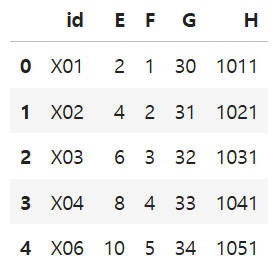
2) inner merge
-왼쪽과 오른쪽 데이터프레임 모두에 존재하는 키(key) 값만 남김(교집합)
-pd.merge(데이터프레임1, 데이터프레임2, on=기준 컬럼명, how=합침 방식)
pd.merge(df3, df4, on='id', how='inner')
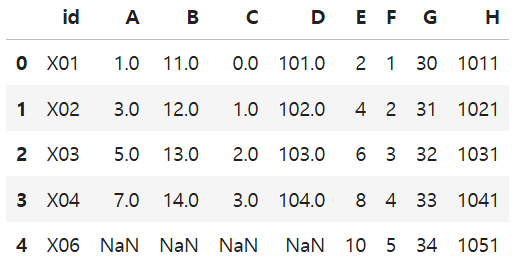
3) outer merge
-왼쪽이나 오른쪽 중 한곳이라도 키가 있으면 모두 가져옴(합집합) → 나머지는 NaN으로 채워짐
pd.merge(df3, df4, on='id', how='outer')

4) left / right merge
-왼쪽 / 오른쪽 데이터프레임의 모든 행을 유지하면서, 오른쪽 / 왼쪽에서 일치하는 데이터를 붙임
pd.merge(df3, df4, on='id', how='left')pd.merge(df3, df4, on='id', how='right')
5) 기준이 되는 컬럼 이름이 서로 다른 경우
df5 = pd.DataFrame({'user_id': ['X01','X02','X03','X04','X06'],
'E': [2,4,6,8,10],
'F': [1,2,3,4,5],
'G': [30,31,32,33,34],
'H': [1011,1021,1031,1041,1051]})
df5-left_on=왼쪽 데이터프레임 컬럼명, right_on=오른쪽 데이터프레임 컬럼명: 이름이 서로 다른 열을 합침
→ 키가 되는 두 열을 모두 결과물에 남겨둠
pd.merge(df3, df5, left_on='id', right_on='user_id')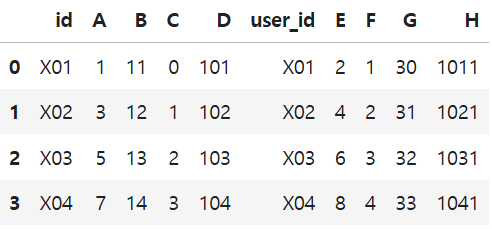
3. join
1) 데이터프레임 준비
df1 = pd.DataFrame({'A': [1,3,5,7,9],
'B': [11,12,13,14,15],
'C': [0,1,2,3,4],
'D': [101,102,103,104,105]},
index = [1,2,3,4,5])
df1df2 = pd.DataFrame({'E': [2,4,6,8,10],
'F': [1,2,3,4,5],
'G': [30,31,32,33,34],
'H': [1011,1021,1031,1041,1051]},
index = [6,7,8,9,10])
df2
2) join 수행
-데이터프레임1.join(데이터프레임2): 인덱스 기준으로 데이터프레임 합쳐짐
df1.join(df2)
3) 인덱스 일치시키기
df1.reset_index(drop=True, inplace=True)
df2.reset_index(drop=True, inplace=True)
df1.join(df2)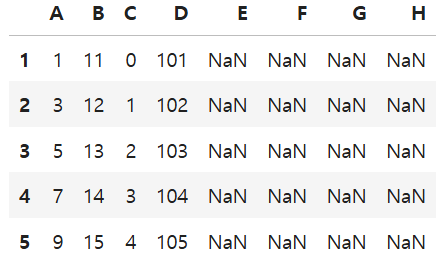

| pd.concat() | pd.merge() | df.join() | |
| 결합 방향 | 수직(위아래) 및 수평(양옆) | 수평 | 수평 |
| 주요 기준 | 인덱스 순서 | 특정 컬럼(Key)의 값 | 인덱스 |
| 기본 조인 방식 | outer(합집합) | inner(교집합) | left(왼쪽 기준) |
| 여러 개 결합 | 가능(리스트 사용) | 한 번에 두 개만 가능 | 가능(인덱스 기준일 때) |
#부트캠프후기 #멀티캠퍼스부트캠프 # 데이터마케팅부트캠프
'부트캠프 > 멀티캠퍼스_퍼포먼스 마케팅과 데이터 분석' 카테고리의 다른 글
| [멀티캠퍼스 부트캠프 10주차(1)] 데이터 분석 심화_딥러닝 (0) | 2026.03.23 |
|---|---|
| [멀티캠퍼스 부트캠프 9주차] 데이터 분석 심화_머신러닝 비지도학습 (1) | 2026.03.23 |
| [멀티캠퍼스 부트캠프 8주차] 데이터 분석 심화_머신러닝 (0) | 2026.03.09 |
| [멀티캠퍼스 부트캠프 7주차(2)] 데이터 분석 심화_선형회귀 모델 (0) | 2026.02.24 |
| [멀티캠퍼스 부트캠프 7주차(1)] 데이터 분석 심화_검정의 이해 (0) | 2026.02.20 |



