데이터 분석 심화_머신러닝 비지도학습
비지도 학습의 이해
1. 지도 학습(Supervised Learning)과 비지도 학습(Unsupervised Learning)
1) 지도 학습 vs. 비지도 학습
-지도 학습: 정답(레이블)이 명시된 데이터를 학습하여 새로운 입력값에 대한 결과 예측
-비지도 학습: 정답 없이 데이터 자체의 특성과 패턴을 분석하여 숨겨진 구조나 특징을 찾아냄
| 지도 학습 | 비지도 학습 | |
| 방법 | 정답을 보며 답을 잘 맞추도록 학습 | 정답 없이 데이터가 가진 특징 학습 |
| 목표 | -데이터 기반의 예측 및 추론 -1:1 대응의 최적 예측기 생성 |
-데이터의 특성 파악 및 요약 -명시된 명확한 출력이 없다면 최적의 출력 탐색 |
| 사용 시기 | 데이터 분석의 목적이 명확하게 설정된 경우 | 분석의 목적이 명확하지 않으며 다양한 시도가 필요한 경우 |
| 유형 | 회귀, 분류 | 그룹화, 차원 축소 |
| 예시 | 주가 예측, 이상 거래 탐지, 고객의 재구매 예측 | 고객 세분화, 노이즈 제거 |

2) 비지도 학습의 주요 유형
①군집화(Clustering)
-레이블이 없는 데이터를 유사점에 따라 그룹화
-K-means 군집화, 계층적 군집화(HCA), 확률적 군집화(GMM)
②차원 축소(Dimension Reduction)
-데이터의 무결성을 보존하면서 변수의 개수를 줄여 핵심 정보만 남김
-주성분 분석(PCA), 비정칙 값 분해(SVD), 오토인코더(Autoencoder)
③연관 규칙(Association Rule)
-데이터 세트 내 변수들 사이의 숨겨진 관계 발견하는 규칙 기반 학습
-Apriori 알고리즘, Eclat, FP-Growth
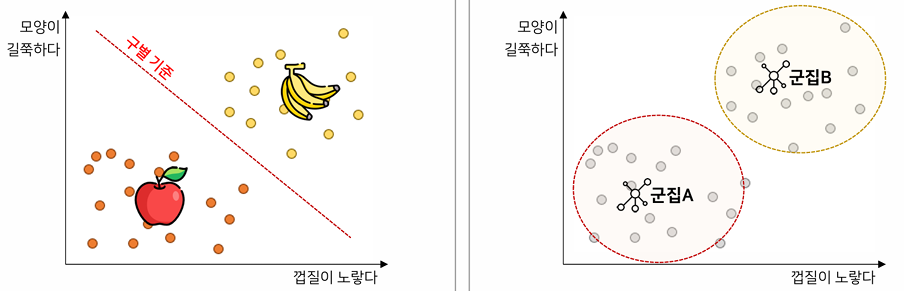
2. 군집화란
1) 군집화의 정의 및 수행 단계
-그룹화란 데이터를 특정 기준에 따라 나누고 묶는 과정
①유사성 측정: 유클리드 거리, 맨하탄 거리 등을 사용해 데이터 포인트 간의 차이 계산
②데이터 그룹화: 측정된 유사성을 바탕으로 데이터를 여러 군집으로 나눔
③중심점(대표값) 설정 및 데이터 할당: 각 준집의 중심을 정의하고 데이터를 해당 중심에 따라 할당
④군집의 품질 평가: 군집 내 응집도와 군집 간 분리도를 계산하여 실루엣 계수 등으로 품질 평가
2) 군집화의 이점
-평균, 중앙값 등의 통계적 계산을 각 그룹별로 쉽게 수행 가능
-특정 그룹 내에서 나타나는 경향이나 패턴 발견하기 용이
-그룹화된 데이터를 활용해 더 명확하고 직관적인 시각화가 가능해 데이터 이해가 쉬움
-방대한 양의 데이터를 작은 단위로 나누어 처리함으로써 데이터 처리의 효율성 높일 수 있음
3) 군집화 vs. 분류
-군집화: 사전에 정해진 라벨이 없으며, 데이터 간의 유사도가 높은 것끼리 묶어 스스로 집합체를 만듦
-분류: 사전에 정의된 클래스가 존재하며, 학습된 기준에 따라 새로운 데이터를 특정 클래스에 할당
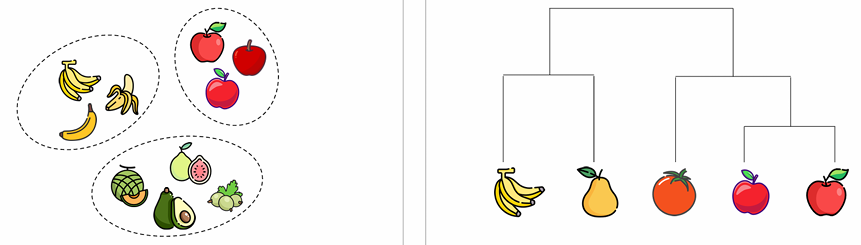
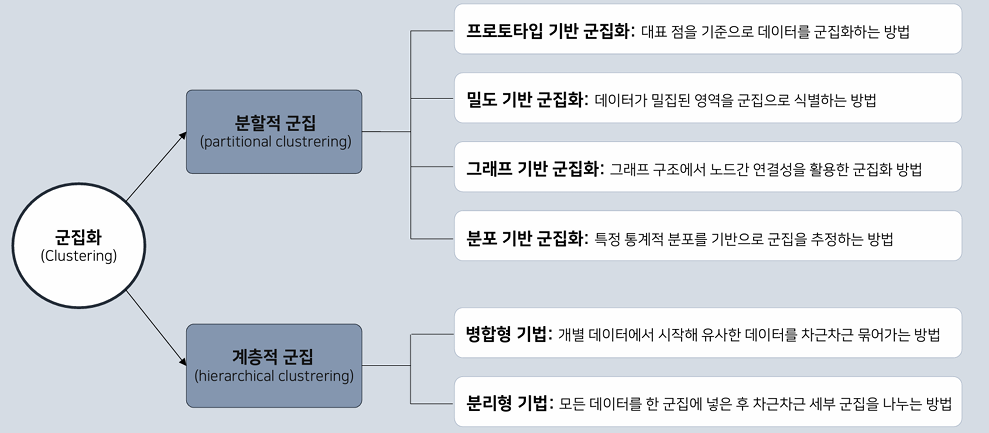
4) 군집화 알고리즘의 유형
-분할적 군집(partitional clustering): 데이터를 비계층적으로 나누며, 각 군집은 독립적(오직 하나의 군집에만 속하며, 겹침 X)
-계층적 군집(hierachical clustering): 트리 구조로 군집화되며, 하위 군집이 상위 군집에 포함될 수 있음
k-means 군집화
1. k-means 군집화의 개념 및 작동 방식
1) k-means 군집화란?
-주어진 데이터를 k개 군집으로 묶는 알고리즘
-k개의 군집을 임의의 중심점(centroid)으로 지정하고, 각 데이터를 가장 가까운 중심점에 할당하며 군집 형성 후 중심점 갱신
-k란 묶을 군집의 개수를 뜻하며, 분석자가 직접 설정해야 하는 하이퍼퍼라미터
2) k-means 알고리즘의 단계
-군집 개수 k 설정: 몇 개의 군집으로 나눌지 결정(Elbow method, Information criterion 등을 사용)
→ 초기 중심점 설정: 각 군집의 무게중심인 중심점 설정(통상적으로 k-means++ 기법 사용)
→ 데이터 군집에 배정: 거리상 가장 가까운 중심점에 각 데이터 할당
→ 중심점 재설정: 각 군집에 속한 데이터들의 평균 지점으로 중심점 재설정
→ 반복: 중심점의 이동이 없을 때까지 3~4단계를 반복하며 최적의 위치 확정

2. 군집화 품질 평가
1) 실루엣 계수
-군집화의 품질을 평가하는 지표로, 각 데이터가 자신의 군집에 얼마나 잘 맞는지 측정(-1~1)
-1에 가까울수록 해당 데이터가 자신이 속한 군집에 잘 맞고 다른 군집과 명확히 구분됨을 의미(Clear-cut)
-0에 가까울수록 군집 간 경계에 위치하여 군집화가 모호함을 의미(Weak)
--1에 가까울수록 데이터가 잘못된 군집에 속해 있음을 의미
2) 실루엣 계수의 계산
-a(i): 데이터 포인트 i가 속한 군집 내 다른 포인트들과의 평균 거리(응집도)
-b(i): 데이터 포인트 i와 가장 가까운 이웃 군집 포인트들과의 평균 거리(분리도)
-s(i) = {b(i) - a(i)} / max(a(i), b(i))


#부트캠프후기 #멀티캠퍼스부트캠프 # 데이터마케팅부트캠프
'부트캠프 > 멀티캠퍼스_퍼포먼스 마케팅과 데이터 분석' 카테고리의 다른 글
| [멀티캠퍼스 부트캠프 11주차] 데이터 분석 심화_자연어 처리 (0) | 2026.03.25 |
|---|---|
| [멀티캠퍼스 부트캠프 10주차(1)] 데이터 분석 심화_딥러닝 (0) | 2026.03.23 |
| [멀티캠퍼스 부트캠프 8주차(2)] 데이터 분석 심화_머신러닝 실습 (0) | 2026.03.11 |
| [멀티캠퍼스 부트캠프 8주차] 데이터 분석 심화_머신러닝 (0) | 2026.03.09 |
| [멀티캠퍼스 부트캠프 7주차(2)] 데이터 분석 심화_선형회귀 모델 (0) | 2026.02.24 |


