데이터 분석 기본_파이썬 기초(자료구조, 판다스)
자료구조
1. 스택과 큐
-스택: Last in first out
-큐: First in first out
2. 튜플과 세트
1) 튜플
-()
-값 변경이 불가한 리스트
-인덱싱[], 슬라이싱, 연산, len 함수 등이 리스트와 동일하게 작동
-튜플 사용하는 경우
- 공동 작업 시 내가 만든 데이터를 다른 사람이 수정하지 못하도록
- 수정 필요 없는 데이터 확인용(빠르게 출력해볼 때)
t = (1, 2, 2, 3)
print(t)
# >>> (1, 2, 2, 3)
2) 세트
-{}
-중복 없이 데이터 저장(unique 값만 추출)
-set(변수명): 세트 안 요소들의 중복 제거
-순서가 없는 자료형 → 인덱스로 접근 불가
s = {1, 2, 2, 3}
s
# >>> {1, 2, 3}r = [1, 2, 3, 2, 3]
print(r) # >>> [1, 2, 3, 2, 3]
set(r) # >>> {1, 2, 3}
3. 딕셔너리
-{}
-키(key)와 값(value)를 짝으로 저장
-변수명 = {key1: value1, key2: value2, ...}
-key의 타입은 숫자, 문자열 모두 가능
-딕셔너리는 순서 x
-변수명[key값]: key 값으로 value를 찾음(인덱싱 사용)
# 딕셔너리 생성_대학생 인적사항
student_info = {20140012: 'Sungchul', 20140059: 'Jiyoung', 20150234: 'Jaehong'}
# → 학번이 key이고 이름이 value인 딕셔너리 생성됨
# Q. 학번이 20140012인 학생은?
student_info[20140012]
# >>> 'Sungchul'-.keys(): 딕셔너리에서 key만 출력
-.values(): 딕셔너리에서 value만 출력
-.items(): key와 value를 쌍으로 모두 출력
넘파이와 판다스 라이브러리
-라이브러리(library): 누군가 미리 짜둔 코드
-특정 함수들을 담고 있음
-기본적인 라이브러리들은 아나콘다 설치 때 다운 완료
-추가적인 라이브러리들은 다운 필요
1. 넘파이(numpy): 수학, 행렬 라이브러리
-넘파이 버전 확인 및 변경
# 넘파이 불러오기
import numpy as np
# 넘파이 버전 확인
np.__version__
# 넘파이 버전 변경(딱히 변경할 필요 x)
!pip uninstall numpy
!pip install numpy=='2.1.3'-1차열 배열(array) → 리스트와 유사
-2차원 배열(행렬)
-고차원(ndarray)
# 1차원 배열
np.array([1, 2, 6])
# >>> array([1, 2, 6])
# 2차원 배열
np.array([[1, 2], [3, 4]]) # 리스트 안에 리스트가 들어간 형태
# >>> array([[1, 2]
[3, 4]])
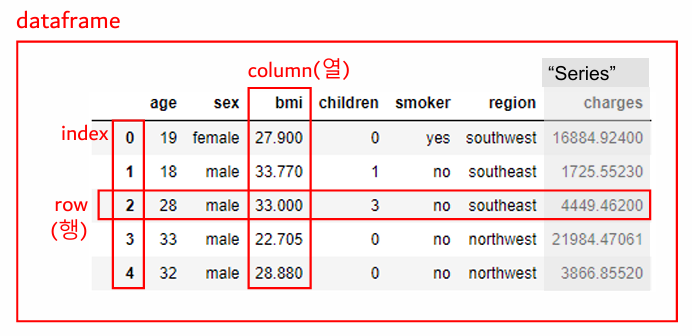
2. 판다스(pandas): 파이썬에서 엑셀처럼 데이터를 다룰 수 있게 해주는 도구
1) 데이터 특성 확인
-1차원(시리즈)
-2차원(데이터프레임)
-csv, 엑셀 파일 불러와서 분석 → 데이터프레임(df) 형태
# 데이터 폴더 세팅
# python_multicampus/data
# 실행중인 주피터 파일과 data 파일이 같은 경로 내에 있어야 함
import pandas as pd
df_ins = pd.read_csv("data/insurance.csv") # ds_ins라는 변수명에 저장
df_ins
# 보험 고객에 대한 정보
# 나이, 성별, bmi, 자녀 수, 흡연 여부, 지역, 보험료, 보험 종류, 가입 기간
-.shape: 데이터 확인 → 데이터(행) 개수, 컬럼/피처(열) 개수
df_ins.shape
# >>> (1353, 9)-.head(n): 상위 데이터 n개 확인
df_ins.head(2)
2) 특정 데이터 추출(컬럼명)
-데이터프레임["컬럼명"]: 한 컬럼만 선택(series)
df_ins["charges"]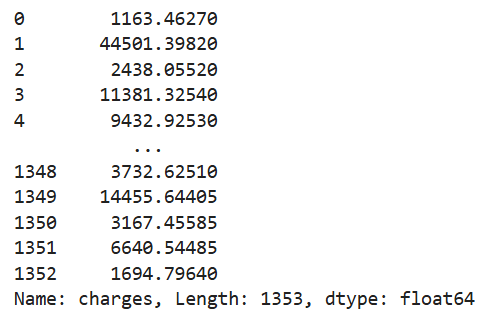
-.mean(): 판다스에서 평균 구하는 함수
-:.nf: 소수점 아래 n자리까지 표현
컬럼 시리즈로 나이 추출하고 평균 나이 구하기
age = df_ins["age"]
print(f"평균 나이: {age.mean():.2f}세")
# >>> 평균 나이: 39.21세-두 개 이상의 컬럼은 리스트[]로 묶어서 선택
# 나이, bmi 데이터만 선택하기
df_ins[["age", "bmi"]]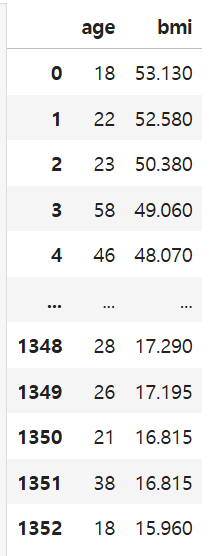
3) 특정 데이터 추출(조건)
-데이터프레임[조건]: 데이터프레임에서 조건으로 데이터 찾기
# 나이가 30세 이상인 데이터 찾기
# df_ins["age"] >= 30 # → True/False 형식으로 나옴(조건의 역할을 함)
df_ins[df_ins["age"] >= 30] # → 30세 이상만 추출됨※ df_ins[50 > df_ins["age"] >= 30]은 불가
(if문에서는 가능했음)
-2개의 조건으로 데이터프레임에서 데이터 추출
- 데이터프레임[(조건1) & (조건2)]: and 조건
- 데이터프레임[(조건1) | (조건2)]: or 조건
# 남성이면서 나이가 30세 이하인 데이터 추출
df_ins[(df_ins['sex'] == 'male') & (df_ins['age'] <= 30)]
# 가독성 고려
cond1 = df_ins['sex'] == 'male'
cond2 = df_ins['age'] <= 30
df_ins[cond1 & cond2] # 변수명은 괄호로 감싸지 않아도 됨※ df_ins[df_ins['sex'] == 'male' & df_ins['age'] <= 30]
→ TypeError 발생('male' & df_ins['age']의 이상한 비트 연산이 먼저 수행되기 때문)
→ 각 조건을 반드시 괄호로 감싸거나 비교 연산을 먼저 끝내도록 해야 함
# 나이가 25세 이하이거나 charges가 50000 이상인 데이터 추출
cond3 = df_ins['age'] <= 25
cond4 = df_ins['charges'] >= 50000
df_ins[cond3 | cond4]
4) 데이터프레임 인덱싱
-데이터프레임.iloc[행 인덱스, 열 인덱스]: 데이터프레임에서 인덱스(위치)로 인덱싱 → 범위 인덱싱으로 확장 可
df_ins.iloc[0, 4]
# >>> 'no' → index 0인 사람의 smoker에 대한 값
df_ins.iloc[0:3, 2]
# >>> 0 53.13
# 1 52.58
# 2 50.38
# Name: bmi, dtype: float64 → index 0~2인 사람의 bmi에 대한 값-데이터프레임.loc[행 이름, 열 이름]: 데이터프레임에서 컬럼명으로 인덱싱 → 범위 인덱싱으로 확장 可
df_ins.loc[0, 'bmi'] # 현재 데이터에서는 행 이름이 인덱스(숫자)로 명명되어있음
# >>> 53.13
df_ins[0:3, 'children':'charges']
# children smoker region charges
# 0 0 no southeast 1163.4627
# 1 1 yes southeast 44501.3982
# 2 1 no southeast 2438.0552
# 3 0 no southeast 11381.3254※ .loc[]은 범위 맨 마지막까지 포함해서 가져옴
"데이터의 활용 가능성과 방법을 고려하여 가치 만들기"
#부트캠프후기 #멀티캠퍼스부트캠프 # 데이터마케팅부트캠프
'부트캠프 > 멀티캠퍼스_퍼포먼스 마케팅과 데이터 분석' 카테고리의 다른 글
| [멀티캠퍼스 부트캠프 5주차(1)] 데이터 분석 기본_웹 통신 개념 (0) | 2026.02.03 |
|---|---|
| [멀티캠퍼스 부트캠프 4주차(2)] 데이터 분석 기본_집계와 시각화 (0) | 2026.02.02 |
| [멀티캠퍼스 부트캠프 3주차] 데이터 분석 기본_파이썬 기초(조건문과 반복문, 함수 기초) (2) | 2026.01.20 |
| [멀티캠퍼스 부트캠프 2주차] 광고 플랫폼 이해_콘텐츠 기획, 뉴미디어(X, 당근, 토스), META, 카카오, 구글 (0) | 2026.01.13 |
| [멀티캠퍼스 부트캠프 1주차] 광고 플랫폼 이해_퍼포먼스 마케팅 개론, 네이버 검색 광고 (1) | 2026.01.06 |



